potatosalad blog
Time-Out: Elixir State Machines versus Servers
13 Oct, 2017I love gen_statem (and the Elixir wrapper gen_state_machine).
Prior to the addition of gen_statem in OTP 19, the decision of when to use gen_server and gen_fsm was a carefully considered one. In the vast majority of my use cases, a simple gen_server was the easiest solution; even if it technically was behaving as a state machine.
Initially, I thought of gen_statem only as a gen_fsm replacement and assumed I would rarely need it over using gen_server.
Lately, however, I find myself reaching for gen_statem to solve problems that I would have previously solved with gen_server.
TL;DR Try using gen_statem instead of gen_server (especially if you plan on using :erlang.start_timer/3). You may find it’s a better fit than you think.
Comparison
Quick comparison between gen_server and gen_statem, using the Stack example in Elixir’s GenServer documentation.
Note: I’m going to use the actual Erlang behaviours instead of Elixir’s GenServer and GenStateMachine so that more details are present.
defmodule StackServer do
@behaviour :gen_server
@impl :gen_server
def init(data) do
{:ok, data}
end
@impl :gen_server
def handle_call(:pop, _from, [head | tail]) do
{:reply, head, tail}
end
@impl :gen_server
def handle_cast({:push, item}, data) do
{:noreply, [item | data]}
end
end
# Start the server
{:ok, pid} = :gen_server.start_link(StackServer, [:hello], [])
# This is the client
:gen_server.call(pid, :pop)
#=> :hello
:gen_server.cast(pid, {:push, :world})
#=> :ok
:gen_server.call(pid, :pop)
#=> :world
Pretty simple, right? Let’s see how gen_statem compares.
Note: OTP’s gen_statem has 2 major modes of operation, but for the purpose of this article, only :handle_event_function will be covered.
defmodule StackStateMachine do
@behaviour :gen_statem
@impl :gen_statem
def callback_mode() do
:handle_event_function
end
@impl :gen_statem
def init(data) do
{:ok, nil, data}
end
@impl :gen_statem
def handle_event({:call, from}, :pop, _state, [head | tail]) do
actions = [{:reply, from, head}]
{:keep_state, tail, actions}
end
def handle_event(:cast, {:push, item}, _state, data) do
{:keep_state, [item | data]}
end
end
# Start the server
{:ok, pid} = :gen_statem.start_link(StackStateMachine, [:hello], [])
# This is the client
:gen_statem.call(pid, :pop)
#=> :hello
:gen_statem.cast(pid, {:push, :world})
#=> :ok
:gen_statem.call(pid, :pop)
#=> :world
In this example, the state is nil and is not used.
You’ll notice that instead of a {:reply, _, _} callback tuple as used in gen_server, replies are sent by passing “actions” as the last element of the state callback tuple. Replies (one or more) can be sent at any time and not necessarily as a synchronous operation resulting from a call event.
Functionally, both examples are equivalent and some may argue that the more concise gen_server implementation is objectively better than the gen_statem version. However, gen_statem really begins to shine, in my opinion, as more and more complexity is added to the implementation.
For example:
- Should elements of the stack expire over time?
- Should certain elements be dropped after a limit has been reached?
- If the stack is empty, should the call block until a new item has been pushed?
- Should the call queue also expire over time?
- What if all of the above is desired?
Time-Outs for Free
The time-out actions included in gen_statem are probably my favorite feature, but they took a while for me to understand.
The gen_statem documentation is excellent, but fairly information-dense and can be difficult to initially digest for some (myself included). It took several reads for me to understand just how powerful time-out actions could be.
There are 3 built-in types of time-out actions…
| Time-Out | Cancellation | Cancelled When… |
|---|---|---|
| Event | Automatic | Any event handled |
| State | Automatic/Manual | Reset to :infinity or state changes |
| Generic | Manual | Reset to :infinity |
The basic types and syntax for time-outs are as follows:
# Types
@type event_type() :: :timeout
@type state_type() :: :state_timeout
@type generic_type() :: {:timeout, term()}
@type timeout_type() :: event_type() | state_type() | generic_type()
@type timeout_time() :: :infinity | non_neg_integer()
@type timeout_term() :: term()
@type timeout_tuple() :: {timeout_type(), timeout_time(), timeout_term()}
# Event Time-Out Example
actions = [{:timeout, 1000, :any}]
@spec handle_event(:timeout, :any, state :: term(), data :: term())
# State Time-Out Example
actions = [{:state_timeout, 1000, :any}]
@spec handle_event(:state_timeout, :any, state :: term(), data :: term())
# Generic Time-Out Example
actions = [{{:timeout, :any}, 1000, :any}]
@spec handle_event({:timeout, :any}, :any, state :: term(), data :: term())
To “reset to :infinity” for state and generic time-outs, you would simply do…
# State Time-Out Cancellation
actions = [{:state_timeout, :infinity, nil}]
# Generic Time-Out Cancellation
actions = [{{:timeout, :any}, :infinity, nil}]
Event Time-Out
I rarely use event time-outs due to their volatility. Any event will cancel them.
## Event Time-Out: Stop after 1 second example ##
@impl :gen_statem
def init(_) do
actions = [{:timeout, 1000, :stop_after_one_second}]
{:ok, nil, nil, actions}
end
@impl :gen_statem
# Event Timeout Events
def handle_event(:timeout, :stop_after_one_second, _state, _data) do
:stop
end
There is no way to manually cancel an event time-out.
Any event handled effectively cancels the time-out…
## Event Time-Out: Automatic cancellation example ##
@impl :gen_statem
def init(_) do
# Send a message to myself after 0.5 seconds
_ = :erlang.send_after(500, :erlang.self(), :cancel_event_timeout)
actions = [{:timeout, 1000, :stop_after_one_second}]
{:ok, nil, nil, actions}
end
@impl :gen_statem
# Info Events
def handle_event(:info, :cancel_event_timeout, _state, _data) do
:keep_state_and_data
end
State Time-Out
State time-outs, however, survive any event that doesn’t reset them or change the state.
For example: a connection time-out for a socket. I might set the state to :connecting and start the connection process which consists of many individual events. If the state is still :connecting after 5 seconds, I might want to change the state to :disconnected and retry the connection process after waiting for a few seconds with another state time-out. If it’s successful, I could change the state to :connected, which would cancel any existing state time-outs.
## State Time-Out: Stop after 1 second example ##
@impl :gen_statem
def init(_) do
actions = [{:state_timeout, 1000, :stop_after_one_second}]
{:ok, nil, nil, actions}
end
@impl :gen_statem
# State Timeout Events
def handle_event(:state_timeout, :stop_after_one_second, _state, _data) do
:stop
end
There are two ways to cancel a state time-out.
First, setting the state time-out to :infinity will cancel the time-out…
## State Time-Out: Manual cancellation example ##
@impl :gen_statem
def init(_) do
# Send a message to myself after 0.5 seconds
_ = :erlang.send_after(500, :erlang.self(), :cancel_state_timeout)
actions = [{:state_timeout, 1000, :stop_after_one_second}]
{:ok, nil, nil, actions}
end
@impl :gen_statem
# Info Events
def handle_event(:info, :cancel_state_timeout, _state, _data) do
actions = [{:state_timeout, :infinity, nil}]
{:keep_state_and_data, actions}
end
Second, changing the state will cancel the time-out…
## State Time-Out: Automatic cancellation example ##
@impl :gen_statem
def init(_) do
# Send a message to myself after 0.5 seconds
_ = :erlang.send_after(500, :erlang.self(), :cancel_state_timeout)
actions = [{:state_timeout, 1000, :stop_after_one_second}]
{:ok, :unstable, nil, actions}
end
@impl :gen_statem
# Info Events
def handle_event(:info, :cancel_state_timeout, :unstable, data) do
{:next_state, :stable, data}
end
Notice that the initial state was :unstable and changing to the :stable state cancelled the state time-out.
Any other events handled that do not change the state or reset the state time-out will result in a :state_timeout event.
Generic Time-Out
Generic time-outs survive any events or state changes and must be manually reset to :infinity in order to be cancelled.
For example: a request time-out, building on top of the socket connection time-out from earlier. At the start of the request, I might set a generic time-out for 30 seconds. I can then try multiple times to connect and reconnect until the request has actually been sent, but if it is still unsuccessful after 30 seconds, it’s time to cancel the request.
## Generic Time-Out: Stop after 1 second example ##
@impl :gen_statem
def init(_) do
actions = [{{:timeout, :generic}, 1000, :stop_after_one_second}]
{:ok, nil, nil, actions}
end
@impl :gen_statem
# Generic Timeout Events
def handle_event({:timeout, :generic}, :stop_after_one_second, _state, _data) do
:stop
end
The only way to cancel a generic time-out is by setting it to :infinity in the same way that state time-outs may be cancelled…
## Generic Time-Out: Manual cancellation example ##
@impl :gen_statem
def init(_) do
# Send a message to myself after 0.5 seconds
_ = :erlang.send_after(500, :erlang.self(), :cancel_generic_timeout)
actions = [{{:timeout, :generic}, 1000, :stop_after_one_second}]
{:ok, nil, nil, actions}
end
@impl :gen_statem
# Info Events
def handle_event(:info, :cancel_generic_timeout, _state, _data) do
actions = [{{:timeout, :generic}, :infinity, nil}]
{:keep_state_and_data, actions}
end
My Favorite Mode
My favorite callback mode for gen_statem is actually [:handle_event_function, :state_enter], which I would recommend for anyone who is trying to start using gen_statem for problem solving.
The main benefits of this callback mode are:
-
Complex State
Your state can technically be any term (not just an atom), which opens up some fairly complex possibilities on what can be done with your state machine.
For example, instead of just
:connectedyou might have state as a tuple{:connected, :heartbeat}or{:connected, :degraded}. You can then pattern match on the state to group together events common to the{:connected, _}state. -
State Enter Events
By default, state enter events (or transition events) are not emitted by
gen_statem, but I have found that they can be very useful to help reduce code complexity. This is especially noticeable with state time-outs that need to be started immediately after changing state.For example:
handle_event(:enter, :disconnected, :disconnected, _data)This means that my
init/1callback function returned something like{:ok, :disconnected, data}, so:disconnectedis my intial state.I might return a
{:state_timeout, 0, :connect}to immediately attempt a connection and transition to the:connectingstate. If that fails, I might transition back to the:disconnectedstate, which would emit:handle_event(:enter, :connecting, :disconnected, _data)In this case, I might want to wait for 1 second by returning
{:state_timeout, 1000, :connect}to delay reconnecting.Typically, I tend to combine these two cases into a single handler:
def handle_event(:enter, old_state, :disconnected, _data) do actions = if old_state == :disconnected do [{:state_timeout, 0, :connect}] else [{:state_timeout, 1000, :connect}] end {:keep_state_and_data, actions} end
In general, I have found the aforementioned callback mode to be the most versatile and useful to better solve otherwise complicated problems.
Hopefully, GenStateMachine will one day be part of Elixir core and you’ll be able to write the following without any external dependencies:
defmodule MyStateMachine do
use GenStateMachine, callback_mode: [:handle_event_function, :state_enter]
# ...
end
Until then, you can use the gen_statem behaviour directly or add gen_state_machine as a dependency to your mix file.
Load Testing cowboy 2.0.0-rc.1
20 Aug, 2017Let’s load test cowboy 2.0.0-rc.1 and see how it compares to cowboy 1.1.2!
Setup
The plan is to use h2load and record the current requests per second while also measuring scheduler utilization.
Since h2load didn’t support this at the time of writing, there is a custom version available at potatosalad/nghttp2@elixirconf2017 which supports printing the current requests per second for a given interval.
Let’s setup the two versions of cowboy we’re going to test:
- cowboy 1.1.2 — released 2017-02-06
- cowboy 2.0.0-rc.1 — released 2017-07-24
Note: This is not a perfectly fair comparison, as cowboy 1.x is HTTP/1.1 only, while cowboy 2.x supports HTTP/2.
cowboy 1.1.2
:cowboy.start_http(Contention.Handler.HTTP, 100, [ port: 29593 ], [
env: [
dispatch: :cowboy_router.compile([{:_, [{:_, Contention.Handler, []}]}])
]
])
defmodule Contention.Handler do
@behaviour :cowboy_http_handler
def init(_transport, req, opts) do
{:ok, req, opts}
end
def handle(req, state) do
{:ok, req} =
:cowboy_req.reply(200, [
{"content-type", "text/plain"}
], "Hello world!", req)
{:ok, req, state}
end
def terminate(_reason, _req, _state) do
:ok
end
end
cowboy 2.0.0-rc.1
cowboy_handler behaviour
:cowboy.start_clear(Contention.Handler.HTTP, [ port: 29593 ], %{
env: %{
dispatch: :cowboy_router.compile([{:_, [{:_, Contention.Handler, []}]}])
}
})
defmodule Contention.Handler do
@behaviour :cowboy_handler
def init(req, opts) do
req =
:cowboy_req.reply(200, %{
"content-type" => "text/plain"
}, "Hello world!", req)
{:ok, req, opts}
end
end
cowboy_stream behaviour
:cowboy.start_clear(Contention.Handler.HTTP, [ port: 29593 ], %{
env: %{
stream_handlers: [ Contention.StreamHandler ]
}
})
defmodule Contention.StreamHandler do
@behaviour :cowboy_stream
def init(_streamid, _req, _opts) do
commands = [
{:headers, 200, %{"content-type" => "text/plain"}},
{:data, :fin, "Hello world!"},
:stop
]
{commands, nil}
end
# ...
end
cowboy 1.x was tested with the following command:
h2load \
--h1 \
--duration=300 \
--warm-up-time=1s \
--clients=100 \
--requests=0 \
'http://127.0.0.1:29594/'
cowboy 2.x was tested with the following command:
h2load \
--duration=300 \
--warm-up-time=1s \
--clients=100 \
--max-concurrent-streams=10 \
--requests=0 \
--window-bits=16 \
--connection-window-bits=16 \
'http://127.0.0.1:29594/'
The test script used is available here:
Results
First, let’s test cowboy 1.x using h2load in HTTP/1.1 mode.

Not bad, an average of ~20k req/s and maximum of ~40k req/s.
Second, let’s test our cowboy 2.x handler using h2load in HTTP/2 mode.

We have a 2x performance gain with an average of ~40k req/s and maximum of ~70k req/s.
Loïc Hoguin, the author of cowboy, mentioned in this issue that using the cowboy_stream behaviour should provide a little extra performance, so let’s test it.

Loïc was right! We gained a 1.5x increase over our handler test and a 3x increase over cowboy 1.x with an average of ~60k req/s and maximum of ~90k req/s.
A few months ago, I started a very unstable experiment to see if I could create a NIF library that Erlang could use to run a HTTP/2 server using libh2o.
I succeeded in creating a very unstable test setup that can actually have a module send responses back to requests received by libh2o.

The average of ~280k req/s and maximum of ~400k req/s is pretty consistent with h2o’s benchmark claims.
In a future post, I will explore the causes of the differences.
Scheduler Utilization
For the extra curious, below are the measured scheduler utilization graphs for each of the tests.
Note: My explanations below are currently in “guess”-form and are not based on any hard evidence. I plan to explore the real reasons for theses numbers in a future post.

For the load test on cowboy 1.x, the schedulers are slightly under utilized. I suspect this is primarily due to the HTTP/1.1 protocol itself where TCP connections are not used nearly as efficiently as in HTTP/2. The extra time is probably spent waiting on I/O.

100% scheduler utilization for the duration of the tests. This is what you might expect to see during a load test.

The stream handler in cowboy 2.x uses a single process per connection. The previous test, however, uses a single process per stream. Therefore, the extra 20% of overhead for the previous test may be due to process creation, scheduling, and garbage collection.

The h2o implementation uses a single process per server. As shown in the graph, only ~12% scheduler utilization is indicative of only 1 of the 8 normal schedulers being fully utilized.
The rest of the work is done by h2o in a single non-scheduler thread event loop.
In a separate implementation not shown here where I spawned a new process for every request (similar to the cowboy 2.x handler), the overall requests per second dropped to ~90k req/s, which is much closer to the performance of cowboy 2.x.
Conclusions
cowboy 2.x is roughly 2-3x faster than cowboy 1.x based on the above load tests.
I am still curious, however, as to whether process-per-request alone is the primary cause for the performance degradation when compared to the ~15x faster results of the makeshift h2o NIF.
Latency of Native Functions for Erlang and Elixir
5 Aug, 2017Erlang and C first appeared within 14 years* of one another.
In the 30+ years together both languages have gone through many changes. The methods of interoperability have also changed with time.
There are now several methods to integrate native functions with Erlang or Elixir code.
My goal in writing this article is to explore these methods and measure latency from the perspective of the Erlang VM.
* Based on C first appearing in 1972 and Erlang first appearing in 1986.
TL;DR Need a native function (C, C++, Rust, etc.) integrated with Erlang or Elixir that is isolation, complexity, or latency sensitive?
Having a hard time deciding whether you should write a node, port, port driver, or NIF?
Use this potentially helpful and fairly unscientific table to help you decide:
| Type | Isolation | Complexity | Latency |
|---|---|---|---|
| Node | Network | Highest | Highest |
| Port | Process | High | High |
| Port Driver | Shared | Low | Low |
| NIF | Shared | Lowest | Lowest |
Overview
Erlang has an excellent Interoperability Tutorial User’s Guide that provides examples for the different ways of integrating a program written in Erlang or Elixir with a program written in another programming language.
The simplest test I could think of to measure the latency was to round trip an Erlang term from the Erlang VM to the native function and back again.
However, the term would need to be large enough to hopefully expose any weaknesses for a given implementation.
Following the guidance from Erlang’s documentation, I implemented slightly more complex examples of the following methods of interoperability:
The NIF and Port Driver implementations have a few different internal strategies for additional comparison (like Dirty NIF and iodata() based port output).
Certain methods should have higher levels of latency based on serialization and isolation requirements. For example, a C Node requires serialization of the entire term in order to pass it back and forth over a TCP connection. A NIF, by comparison, requires no serialization and operates on the term itself in memory.
Each implementation was tested with a ~64KB binary full of 1’s as the sole element of a 1-arity tuple for 100,000 iterations. The measured elapsed time for each method were then fed into HDR Histogram for latency analysis.
In other words, I essentially did the following on the Latency module:
term = {:binary.copy(<<1>>, 1024 * 64)}
Latency.compare(term, 100_000)
C Node/Port versus Port Driver/NIF
First, let’s compare the 4 major types of native functions:
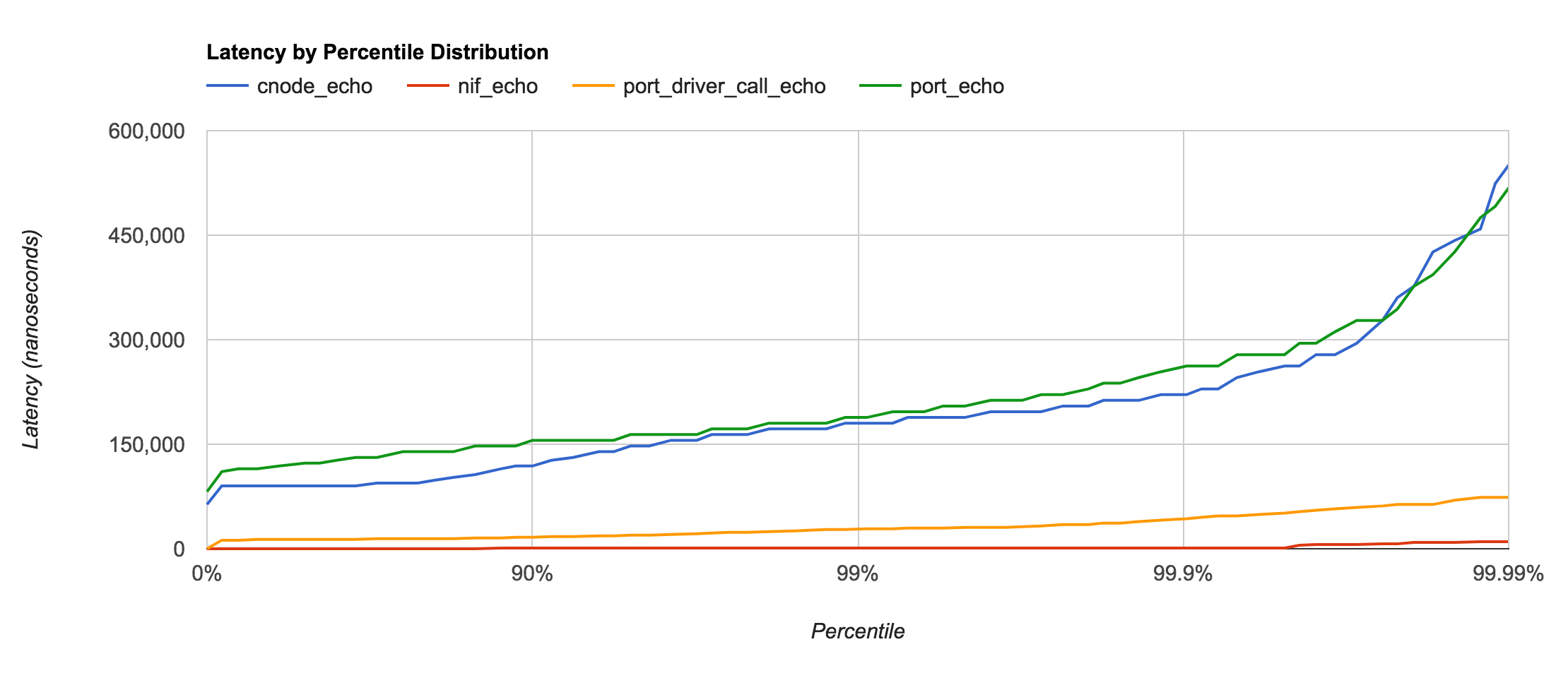
Comparison of results using the order of magnitude of average latency:
| Type | Isolation | Latency |
|---|---|---|
| Node | Network | ~100μs |
| Port | Process | ~100μs |
| Port Driver | Shared | ~10μs |
| NIF | Shared | ~0.1μs |
These tests were run on the same machine, so there’s little surpise that the Node and Port latencies are essentially just benchmarking pipe speeds of the operating system itself (in this case macOS 10.12). Were the Erlang and C nodes located on different machines, I would expect the latency to be higher for the Node test.
It’s also worth noting that C Nodes and Ports are the most isolated form of native function calling from the Erlang VM. This means that a bug in the C code that causes the C Node or Port to crash will not take down the entire VM.
Port Driver
Port drivers, under certain circumstances, can be roughly as fast as a NIF. This is especially true for very small terms or when the majority of the work performed is I/O or binary-based.
The documentation for driver_entry mentions that erlang:port_control/3 should be the fastest way to call a native function. This seems to be true for very small terms, but larger terms cause the performance to be almost identical to erlang:port_call/3. Converting terms to the External Term Format and sending with erlang:port_command/3 (which in turn calls the outputv callback) actually appears to have slightly less latency.
call— lines 61-70 oflatency_drv.ccontrol— lines 41-52 oflatency_drv.coutputv— lines 54-59 oflatency_drv.c
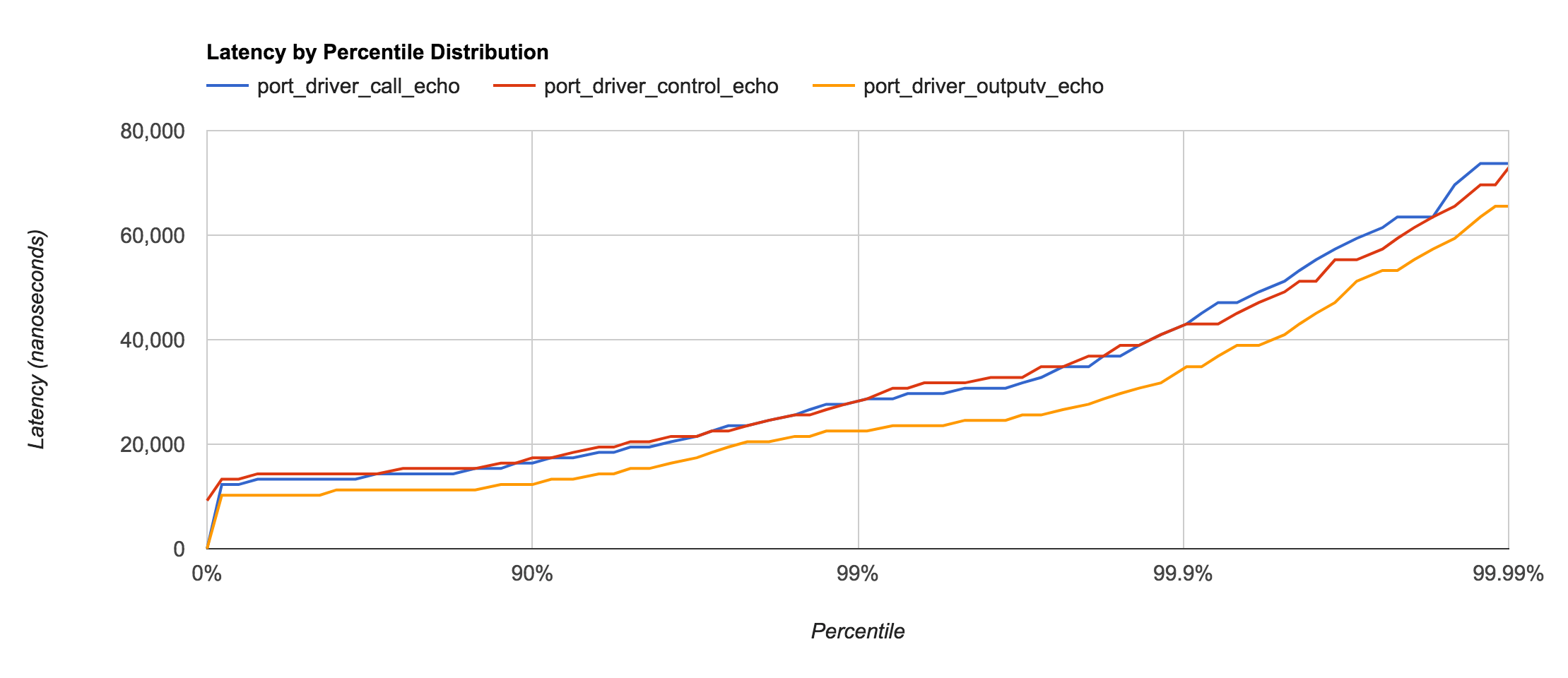
Also worth noting is the type of data allowed to be sent to the Port Driver. For example, erlang:port_call/3 allows terms to be sent, but internally converts them to the external term format. The other types are similar to C Node and Port implementations and require any terms sent to first be converted.
| Type | Data Type | Latency |
|---|---|---|
| call | term() | ~15μs |
| control | iodata() | ~15μs |
| outputv | iodata() | ~10μs |
NIF
Native Implemented Function (NIF) is a relatively recent addition to OTP and is the fastest way to call native functions. However, a mis-behaving NIF can easily destabilize or crash the entire Erlang VM.
Dirty NIF and Yielding (or Future) NIF with enif_schedule_nif are even more recent additions that help prevent blocking the Erlang VM schedulers during execution or (in the case of I/O) waiting.
- Dirty CPU — lines 20-24 of
latency_nif.c - Dirty I/O — lines 26-30 of
latency_nif.c - Future — lines 32-36 of
latency_nif.c - Normal — lines 14-18 of
latency_nif.c
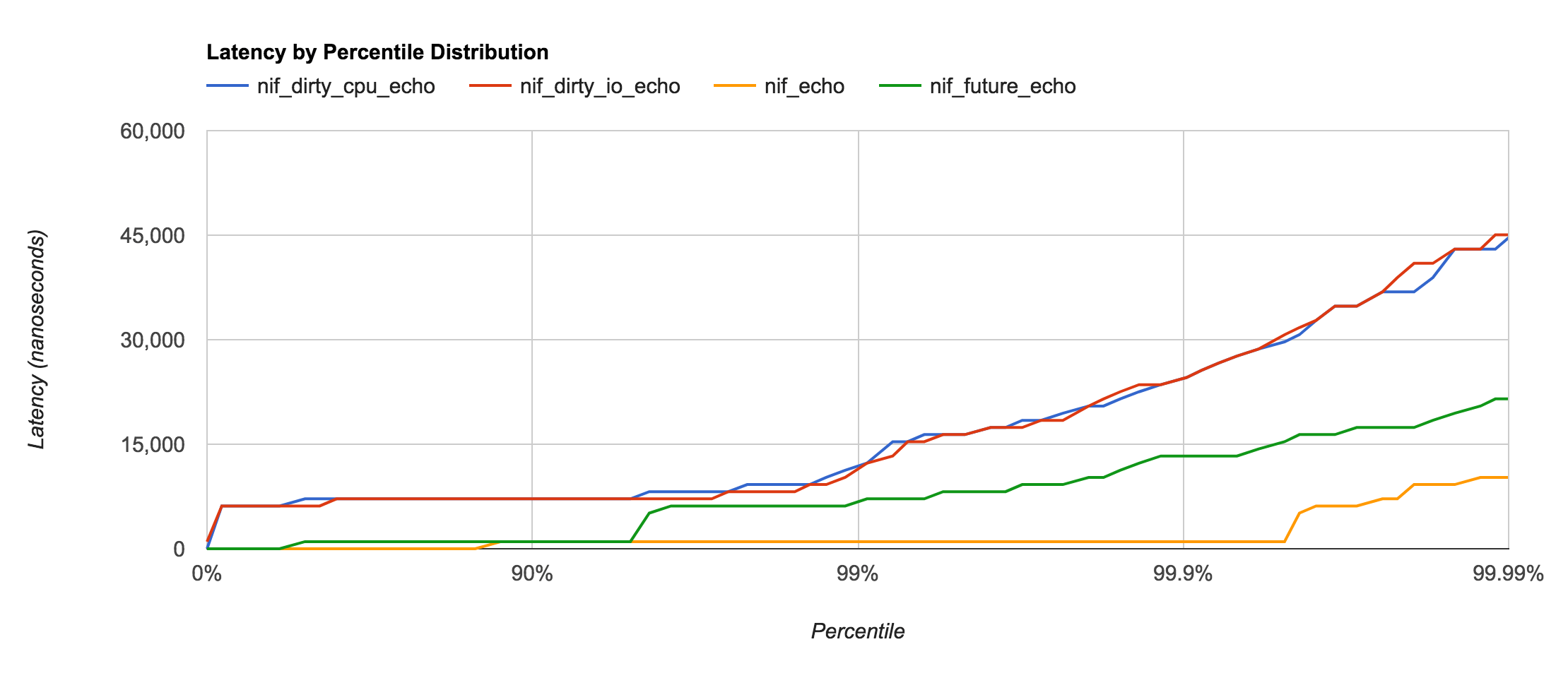
The Normal NIF call is the only one that doesn’t have any sort of context switching involved. The Yielding (or Future) NIF also doesn’t involve much of a context switch as it yields control back to the same scheduler that dispatched the call. Dirty NIF calls, however, result in a ~2μs context switch delay as the function gets enqueued on the dirty thread pool.
| Type | Context Switch | Latency |
|---|---|---|
| Dirty CPU | Thread Queue | ~2.0μs |
| Dirty I/O | Thread Queue | ~2.0μs |
| Future | Yield | ~0.5μs |
| Normal | None | ~0.1μs |
Just for fun, I was curious about the latency differences between the new Dirty NIF functionality and the previous method of using a Threaded NIF or the Async NIF (or Thread Queue) by Gregory Burd.
- Thread New — lines 38-72 of
latency_nif.c - Thread Queue — lines 74-90 of
latency_nif.c
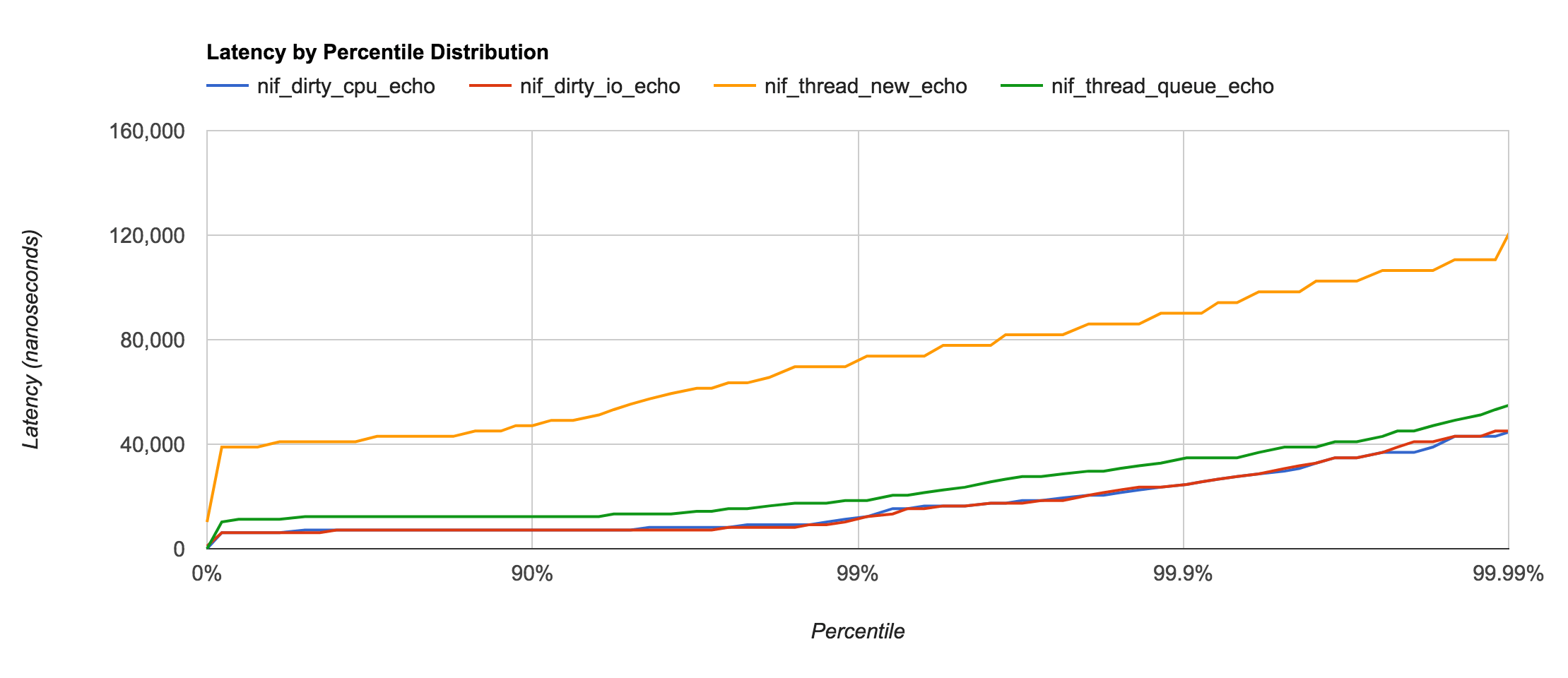
As it turns out, creating and destroying a thread for each and every call is unwise for a few reasons; poor latency being one of them. The Async NIF (or Thread Queue) has the advantage of providing a pool per NIF instead of having to share the global thread pool with other NIFs. However, Dirty NIF thread pools are definitely more optimized and are typically 4x faster than the Async NIF implementation.
| Type | Pool Type | Latency |
|---|---|---|
| Thread New | None | ~50.0μs |
| Thread Queue | NIF | ~8.0μs |
| Dirty CPU | Global | ~2.0μs |
| Dirty I/O | Global | ~2.0μs |
Conclusions
If isolation from/protection of the Erlang VM is highest priority, a C Node or Port are your best options. If your primary concern is low latency or low complexity, using a NIF for your native function is your best option.
As a side note: For very specific I/O operations, a Port Driver still may be the best option. OTP-20 has the new enif_select, which is starting to transition some of those I/O benefits to the NIF world, so this may not be true statement in the near future.
Erlang NIF with timeslice reductions
6 Feb, 2016Recently, I put together an Erlang asynchronous port driver named keccakf1600 which implements the SHA-3 algorithms used in another one of my projects, jose.
See version 1.0.2 of keccakf1600 for the original port driver implementation.
When interfacing with native C and the Erlang VM, you essentially have 3 options to choose from:
- Port Driver — a shared library linked with
driver_entry(I/O heavy operations are typically best suited for this type) - NIF — a shared library linked with
ERL_NIF_INIT(fast synchronous operations are typically best suited for this type) - Port — an external program which typically communicates with the Erlang VM over
stdinandstdout
My goal was to have a fast and asynchronous way to call blocking functions without disrupting the Erlang VM schedulers from carrying out their work. The original plan was to use driver_async combined with ready_async to perform the blocking operations on “a thread separate from the emulator thread.” I used the ei library in order to communicate between the Erlang VM and the port driver written in C.
Having accomplished my goal, I decided to run a simple benchmark against the equivalent SHA-2 algorithms out of curiosity as to how my implementation might stack up against the native Erlang crypto library.
The results were not terribly impressive:

The two main concerns I had with the results were:
- Was the SHA-3 implementation I used (based on ed448goldilocks) really 5-7 times slower than the SHA-2 algorithms?
- Why was there so much variance between the SHA-3 algorithms versus the variance observed between the SHA-2 algorithms?
Concern #1 was ruled out by directly testing the C version of the algorithms, for small message sizes they were typically within 1-2μs of each other.
Concern #2 required more research, which eventually led me to the bitwise project by Steve Vinoski. The project explores some of the strategies for dealing with the synchronous nature of a NIF without blocking the scheduler by keeping track of reductions during a given timeslice. It also explores strategies using the experimental dirty NIF feature.
I highly recommend reading the two presentations from the bitwise project: vinoski-opt-native-code.pdf and vinoski-schedulers.pdf.
After experimenting with the two options, I decided to use enif_consume_timeslice combined with enif_schedule_nif to yield control back to the main Erlang VM on larger inputs to prevent blocking other schedulers.
I rewrote the port driver as a NIF and released it as version 2.0.0 of keccakf1600 and ran the same benchmark again:

These results are much more consistent and closer to my original expectations. I plan on refactoring the erlang-libsodium project using the same technique.
subscribe via RSS