potatosalad blog
Latency of Native Functions for Erlang and Elixir
5 Aug, 2017Erlang and C first appeared within 14 years* of one another.
In the 30+ years together both languages have gone through many changes. The methods of interoperability have also changed with time.
There are now several methods to integrate native functions with Erlang or Elixir code.
My goal in writing this article is to explore these methods and measure latency from the perspective of the Erlang VM.
* Based on C first appearing in 1972 and Erlang first appearing in 1986.
TL;DR Need a native function (C, C++, Rust, etc.) integrated with Erlang or Elixir that is isolation, complexity, or latency sensitive?
Having a hard time deciding whether you should write a node, port, port driver, or NIF?
Use this potentially helpful and fairly unscientific table to help you decide:
| Type | Isolation | Complexity | Latency |
|---|---|---|---|
| Node | Network | Highest | Highest |
| Port | Process | High | High |
| Port Driver | Shared | Low | Low |
| NIF | Shared | Lowest | Lowest |
Overview
Erlang has an excellent Interoperability Tutorial User’s Guide that provides examples for the different ways of integrating a program written in Erlang or Elixir with a program written in another programming language.
The simplest test I could think of to measure the latency was to round trip an Erlang term from the Erlang VM to the native function and back again.
However, the term would need to be large enough to hopefully expose any weaknesses for a given implementation.
Following the guidance from Erlang’s documentation, I implemented slightly more complex examples of the following methods of interoperability:
The NIF and Port Driver implementations have a few different internal strategies for additional comparison (like Dirty NIF and iodata() based port output).
Certain methods should have higher levels of latency based on serialization and isolation requirements. For example, a C Node requires serialization of the entire term in order to pass it back and forth over a TCP connection. A NIF, by comparison, requires no serialization and operates on the term itself in memory.
Each implementation was tested with a ~64KB binary full of 1’s as the sole element of a 1-arity tuple for 100,000 iterations. The measured elapsed time for each method were then fed into HDR Histogram for latency analysis.
In other words, I essentially did the following on the Latency module:
term = {:binary.copy(<<1>>, 1024 * 64)}
Latency.compare(term, 100_000)
C Node/Port versus Port Driver/NIF
First, let’s compare the 4 major types of native functions:
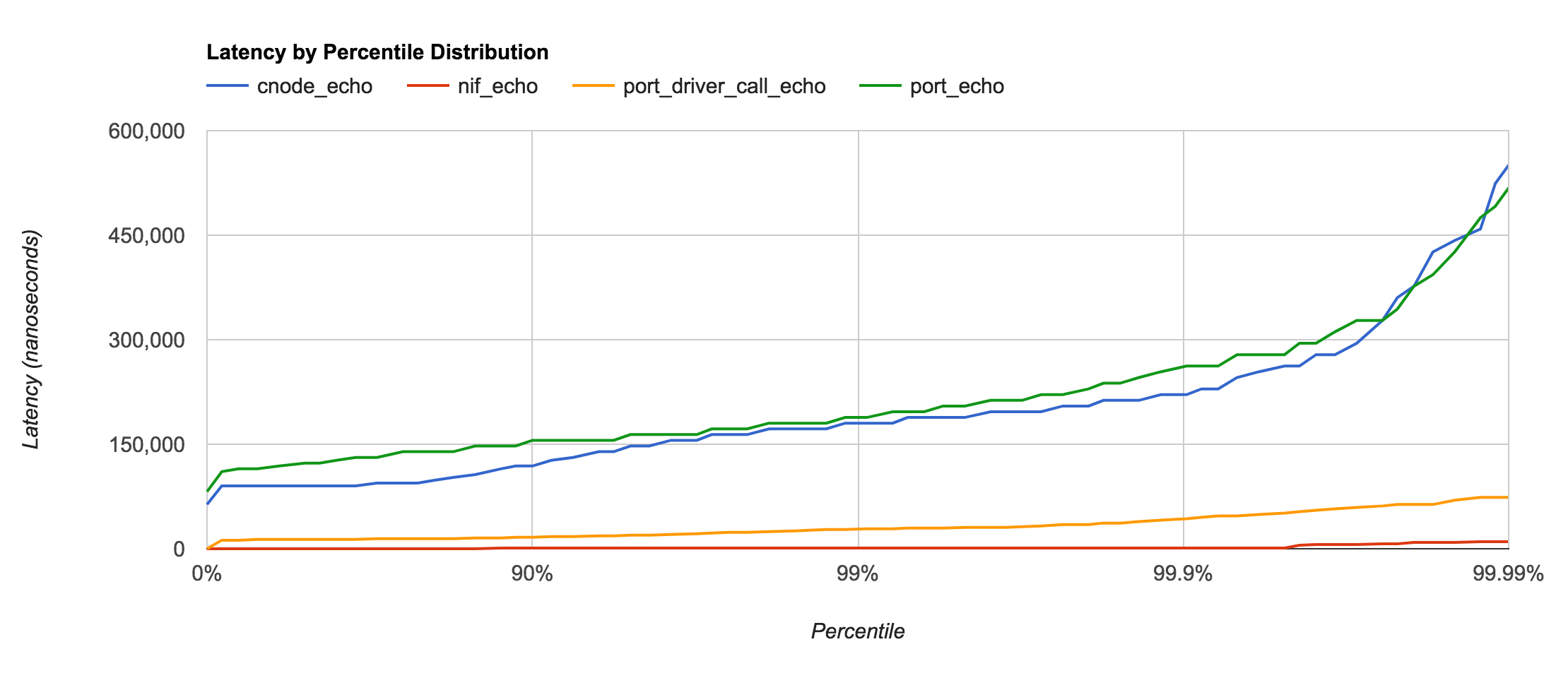
Comparison of results using the order of magnitude of average latency:
| Type | Isolation | Latency |
|---|---|---|
| Node | Network | ~100μs |
| Port | Process | ~100μs |
| Port Driver | Shared | ~10μs |
| NIF | Shared | ~0.1μs |
These tests were run on the same machine, so there’s little surpise that the Node and Port latencies are essentially just benchmarking pipe speeds of the operating system itself (in this case macOS 10.12). Were the Erlang and C nodes located on different machines, I would expect the latency to be higher for the Node test.
It’s also worth noting that C Nodes and Ports are the most isolated form of native function calling from the Erlang VM. This means that a bug in the C code that causes the C Node or Port to crash will not take down the entire VM.
Port Driver
Port drivers, under certain circumstances, can be roughly as fast as a NIF. This is especially true for very small terms or when the majority of the work performed is I/O or binary-based.
The documentation for driver_entry mentions that erlang:port_control/3 should be the fastest way to call a native function. This seems to be true for very small terms, but larger terms cause the performance to be almost identical to erlang:port_call/3. Converting terms to the External Term Format and sending with erlang:port_command/3 (which in turn calls the outputv callback) actually appears to have slightly less latency.
call— lines 61-70 oflatency_drv.ccontrol— lines 41-52 oflatency_drv.coutputv— lines 54-59 oflatency_drv.c
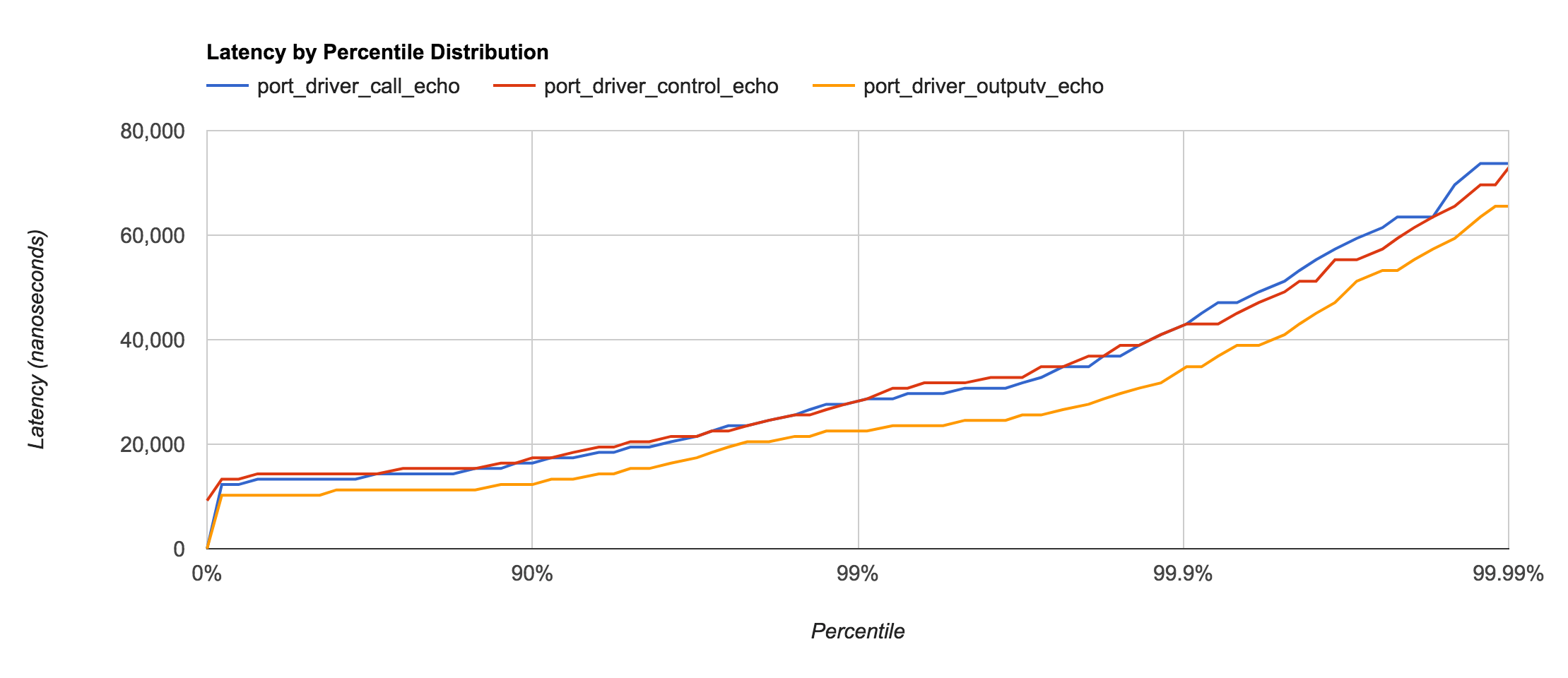
Also worth noting is the type of data allowed to be sent to the Port Driver. For example, erlang:port_call/3 allows terms to be sent, but internally converts them to the external term format. The other types are similar to C Node and Port implementations and require any terms sent to first be converted.
| Type | Data Type | Latency |
|---|---|---|
| call | term() | ~15μs |
| control | iodata() | ~15μs |
| outputv | iodata() | ~10μs |
NIF
Native Implemented Function (NIF) is a relatively recent addition to OTP and is the fastest way to call native functions. However, a mis-behaving NIF can easily destabilize or crash the entire Erlang VM.
Dirty NIF and Yielding (or Future) NIF with enif_schedule_nif are even more recent additions that help prevent blocking the Erlang VM schedulers during execution or (in the case of I/O) waiting.
- Dirty CPU — lines 20-24 of
latency_nif.c - Dirty I/O — lines 26-30 of
latency_nif.c - Future — lines 32-36 of
latency_nif.c - Normal — lines 14-18 of
latency_nif.c
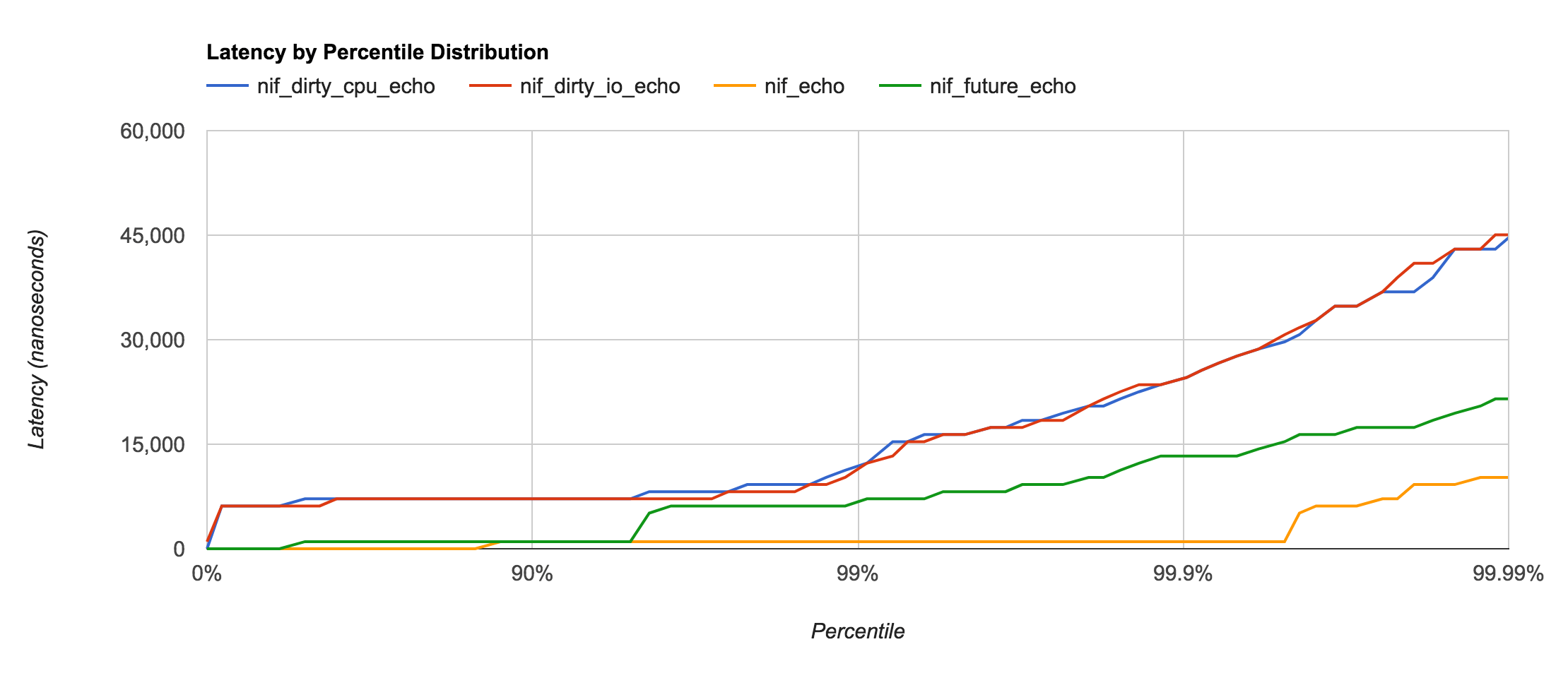
The Normal NIF call is the only one that doesn’t have any sort of context switching involved. The Yielding (or Future) NIF also doesn’t involve much of a context switch as it yields control back to the same scheduler that dispatched the call. Dirty NIF calls, however, result in a ~2μs context switch delay as the function gets enqueued on the dirty thread pool.
| Type | Context Switch | Latency |
|---|---|---|
| Dirty CPU | Thread Queue | ~2.0μs |
| Dirty I/O | Thread Queue | ~2.0μs |
| Future | Yield | ~0.5μs |
| Normal | None | ~0.1μs |
Just for fun, I was curious about the latency differences between the new Dirty NIF functionality and the previous method of using a Threaded NIF or the Async NIF (or Thread Queue) by Gregory Burd.
- Thread New — lines 38-72 of
latency_nif.c - Thread Queue — lines 74-90 of
latency_nif.c
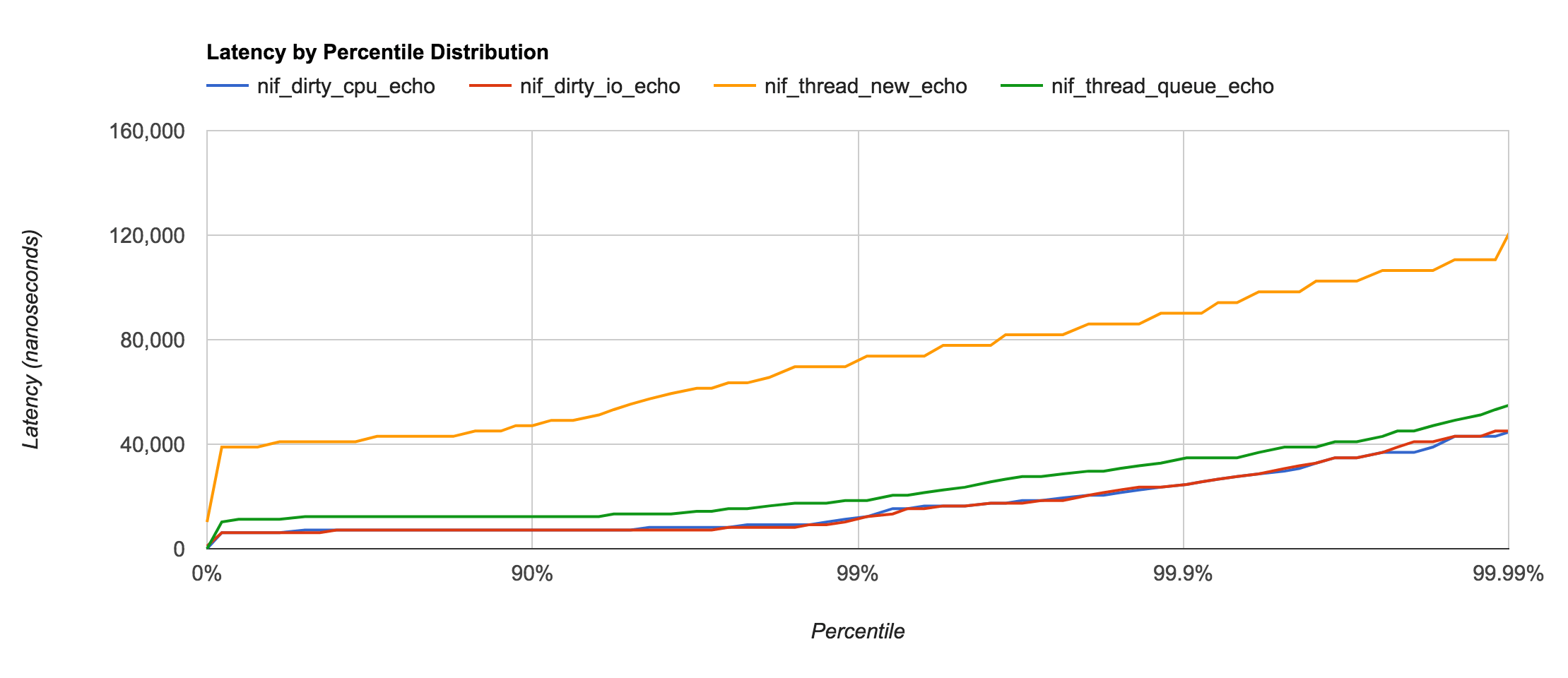
As it turns out, creating and destroying a thread for each and every call is unwise for a few reasons; poor latency being one of them. The Async NIF (or Thread Queue) has the advantage of providing a pool per NIF instead of having to share the global thread pool with other NIFs. However, Dirty NIF thread pools are definitely more optimized and are typically 4x faster than the Async NIF implementation.
| Type | Pool Type | Latency |
|---|---|---|
| Thread New | None | ~50.0μs |
| Thread Queue | NIF | ~8.0μs |
| Dirty CPU | Global | ~2.0μs |
| Dirty I/O | Global | ~2.0μs |
Conclusions
If isolation from/protection of the Erlang VM is highest priority, a C Node or Port are your best options. If your primary concern is low latency or low complexity, using a NIF for your native function is your best option.
As a side note: For very specific I/O operations, a Port Driver still may be the best option. OTP-20 has the new enif_select, which is starting to transition some of those I/O benefits to the NIF world, so this may not be true statement in the near future.